
|
We would like to dedicate this blog post to the Mutual Information Paradigm (MIP) of mechanism construction by Kong and Schoenebeck [3], as well as to its flagship mechanism Determinant Mutual Information (DMI) [1] and mechanism class Volume Mutual Information (VMI) [2]. These mechanisms stood out in the survey of social epistemic mechanisms for content moderation that we conducted in our previous blog post. We believe they already can be used in practical applications, such as a better version of Community Notes.
Recall that our goal is to obtain a mechanism with the following desiderata: truthfulness, collusion resistance, minimalism, agent heterogeneity, simplicity, small population, effort incentivization and flexible risk profiles. With the lottery trick we mentioned, VMI mechanisms such as DMI satisfy all of our desiderata, with the notable exception of collusion resistance and, depending on the point of view, of simplicity, though it is certainly not one of the hardest mechanisms to understand. While the lack of collusion resistance does hinder its employment in a decentralized setting, the ideas behind these mechanisms are so powerful and beautiful that they merit being known. It is also worth understanding how these mechanisms fail in the presence of coalitions, so as to guide future mechanism design.
Concerned with multi-task peer prediction, the MIP assumes a finite set of tasks assigned to \(n \geqslant 2\) agents. Each agent produces an answer from a finite set \(C\) of choices.
Example. Let the tasks be rating the latest community notes and the agents be raters, each of which will respond to each note with an answer in \(C = \left\{ \texttt{helpful}, \texttt{not-helpful} \right\}\), or \(C = \left\{ \texttt{h}, \texttt{n} \right\}\) for short. |
Each task \(t\) has a statistical type \(\theta\), which is a probability distribution \(U^{\theta}_{[n]} \in \Delta_{C^n}\), a fancy way of saying that, with tasks sampled uniformly at random, the probability that a given agent \(\)will come to believe that a given answer is the correct one depends only on the type of the task. In fact, if we let \(X^{\theta}_i\) be a random variable over \(C\) governing the beliefs (also known as signals) agent \(i\) acquires on tasks of type \(\theta\), then for all \(c \in C\),
Example. Suppose we have two agents Alice (number 0) and Bob (number 1), with Alice a member of the political situation and Bob honest and neutral, and we have two Community Notes types \(\theta_0\) and \(\theta_1\), with notes of type \(\theta_0\) coming from the mainstream media and those of type \(\theta_1\) coming from decentralized social media. Since they come from the situation-approved media, Alice is more likely to be biased favorably towards notes of type \(\theta_0\), and more negatively towards those of type \(\theta_1\), usually voiced by the opposition, while Bob focuses on the true helpfulness of the notes themselves. We could have \(\Pr [ X^{\theta_0}_0 = \texttt{h} ] = 0.8\) and \(\Pr [ X^{\theta_0}_1 = \texttt{h} ] = 0.3\), meaning that, just knowing the source of the note is the mainstream media, but before reading it, we know Alice is 80% likely to rate the note as helpful, while Bob is only 30% likely to do so. By contrast, for notes emerging from decentralized social media, Bob's ratings may be 50-50 with \(\Pr [ X^{\theta_1}_1 = \texttt{h}] = 0.5\), but Alice is more likely to reject the notes, say with \(\Pr [ X^{\theta_1}_0 = \texttt{h} ] = 0.25\). |
As we mentioned in our previous blog post, the insight that achieves agent heterogeneity via multi-task peer prediction is moving statistical assumptions away from agents and towards tasks. Thus the first assumption made by the mechanism is that there is only one statistical type of task, which enables us to “drop the superscripts.”
Assumption (A Priori Similar Tasks). All tasks have the same statistical type.
Observation. One simple way of ensuring this assumption holds in practice is to randomize task assignment.
The mechanisms do have one assumption on agents' strategies, but, before we state that assumption, we must understand what a strategy is. Formally, it is, for each input signal, a probability distribution of output signals. It means that whenever an agent is given a task, it will receive its true signal (his genuine belief) of what the correct answer is and then, given this input signal, it will report an output signal at random based on the corresponding distribution.
A simple way to represent a strategy is via (column) stochastic matrices [4], also known as transition matrices. Each column of such a matrix is made of non-negative entries that sum to one and thus represent a probability distribution. A strategy \(S\) is thus a \(C \times C\) matrix where \(S_{\hat{c} c}\) is the probability that the agent will report \(\hat{c}\) given that his true signal is \(c\). The honest reporting strategy, for example, would correspond to the identity matrix.
Example. Let's again consider Alice and Bob, and recall that Alice has an agenda for the political situation, while Bob is honest and neutral (with the identity matrix as his strategy). Suppose that exactly 30% of the Community Notes to rate are pro-establishment and, for simplicity, that the helpfulness of notes is independent of the political leaning, with 50% of notes truly helpful and 50% truly unhelpful. Let's assume as well that both Alice and Bob understand precisely which notes are truly helpful and which ones aren't. Because Alice's commitment is not to the truth, but to the establishment, one strategy she could employ is reporting all pro-establishment notes as helpful and all other notes as unhelpful. Thus, according to this strategy, she will promote 30% of unhelpful notes and demote 70% of helpful notes, resulting in a strategy matrix 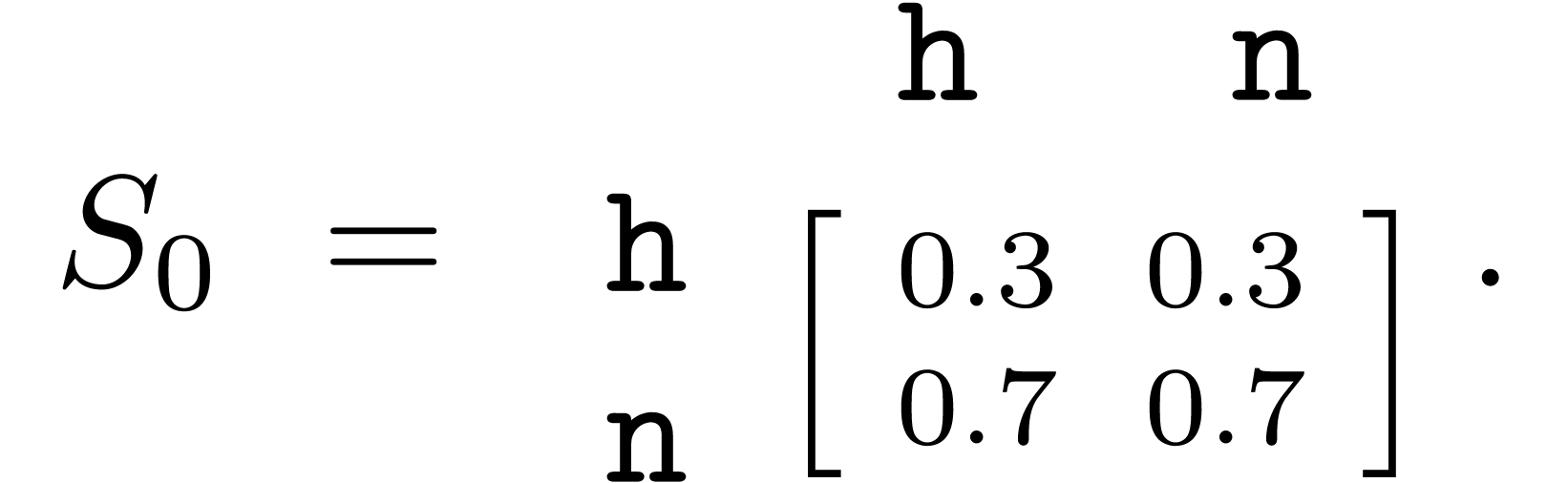 However, that might give away that she is dishonest, so she might try to mask her bias with another strategy: to reject all unhelpful pro-establishment notes but to never accept any counter-establishment note. This would result in the strategy matrix
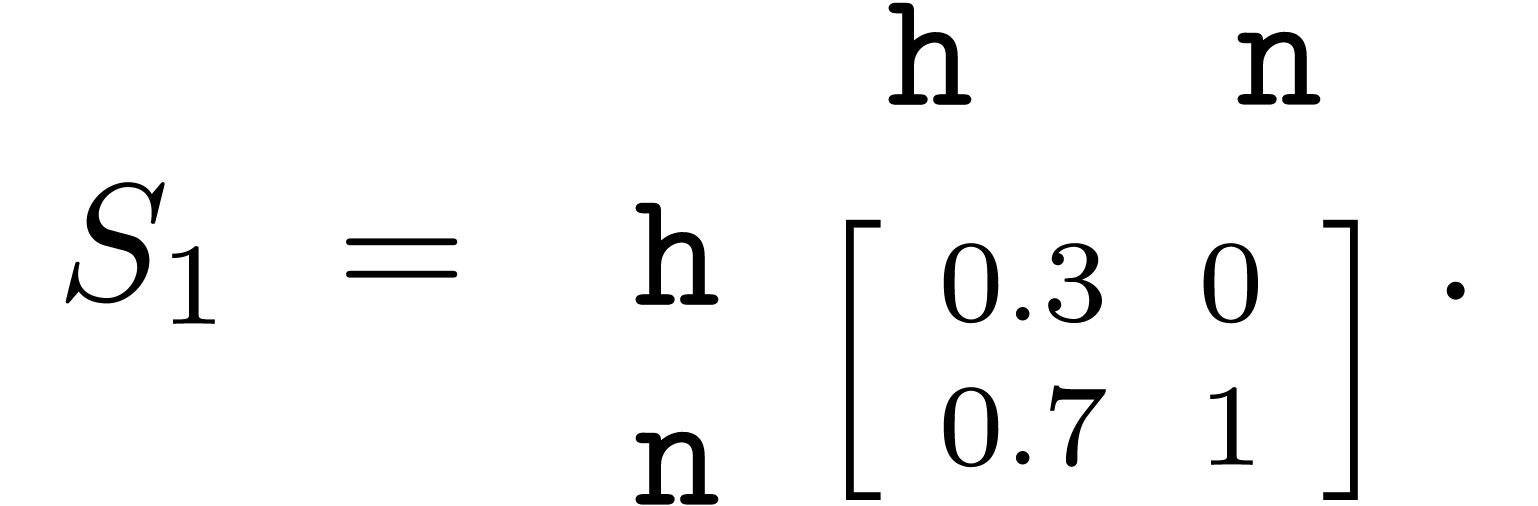
|
One advantage of framing strategies as matrices appears if we interpret the random variable \(X_i\) governing the true beliefs of agent \(i\) as a \(| C |\)-dimensional vector \(\boldsymbol{x}_i\), with \((x_i)_c = \Pr [X_i = c]\). Then if agent \(i\) uses a strategy \(S\), the vector \(\hat{\boldsymbol{x}}_i = S\boldsymbol{x}_i\) corresponds to the random variable \(\hat{X}_i\) governing the actual responses of the agent (with \(\hat{X}_i\) defined analogously).
Now that we understand strategies, we can state the second assumption of the mechanism, which is admittedly difficult to enforce in general.
Assumption (Consistent Strategies). Each agent employs the same strategy for all tasks.
In order to define what is mutual information, let's first denote the joint distribution matrix \(\)of two random variables \(X\) and \(Y\) over \(C\) as \(U_{X Y}\), so \((U_{X Y})_{a b} = \Pr [X = a \wedge Y = b]\). The following proposition, whose proof we leave for the Appendix, establishes the effect of the employment of a strategy on the joint distribution of reports.
Proposition
The key insight is that since \(\hat{X}_i\) is derived from \(X_i\) via
a strategy, it should be less informative of \(\hat{X}_j\) than is
\(X_i\). Thus any function \(\operatorname{MI}\) of \(C \times C\)
matrices that satisfies \(\operatorname{MI} (SU) \leqslant
\operatorname{MI} (U)\) for all joint distribution matrices \(U\) and
stochastic matrices \(S\) can be called a
mutual information measure
Denoting \(\operatorname{MI} (U_{X Y})\) as \(\operatorname{MI} (X, Y)\)
for brevity, such mutual information measures induce dominantly truthful
mechanisms under certain conditions [
2
, Lemma 3.10], as long as they can be accurately estimated
It turns out that every mutual information measure \(\operatorname{MI} (U)\) that is polynomial in the entries of the joint distribution matrix \(U\) can be estimated with only \(d\) samples, where \(d\) is the degree of the polynomial (the maximum monomial degree). This is quite important, as we can estimate \(\operatorname{MI} (\hat{X}_i, \hat{X}_j)\) from the responses of agents \(i\) and \(j\) to \(d\) tasks.
One good candidate for the mutual information measure is the determinant mutual information measure \(\operatorname{DMI} (U) = | \det U |\), which maps a joint probability distribution matrix to the absolute value of its determinant. This works out of the box because the determinant of a transition matrix is always between \(- 1\) and \(1\), and also the determinant of a matrix product is the product of the determinants. However, while the determinant is a polynomial of degree \(| C |\) on the entries of \(U\), the absolute value of the determinant is not. To work around this, we either use the square of the determinant (a polynomial of degree \(2 | C |\)) or an alternative simpler mechanism [2, Section 4.2] with the same payoffs in expectation, so the measure has an unbiased estimator. In either case, it will be a mechanism for \(n \geqslant 2\) agents and \(| T | \geqslant 2 | C |\) tasks. With these considerations, the \(\operatorname{DMI}\) measure gives birth to the determinant mutual information mechanism, which is the first dominantly truthful mechanism in the literature with a finite number of tasks.
Example. Going back to our example with Alice and Bob, because half of the notes are helpful and half are unhelpful, and because Bob reports honestly, the joint distribution of the belief of Alice and the report of Bob is 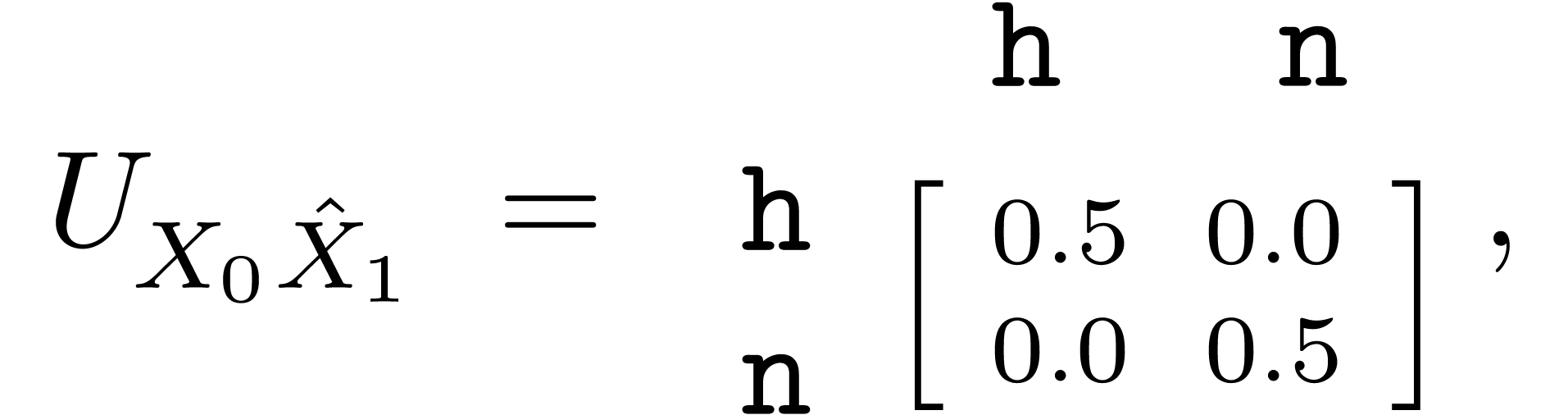
Recall that Alice has two lying strategies \(S_0\) and \(S_1\) at her disposal to try to forward her political agenda. If she chooses \(S_0\), then If she chooses \(S_1\), then However, so Alice is heavily punished by choosing a lying strategy over the truth-telling one. Bob is also punished when Alice is his peer, but Alice is only one of Bob's peers, while Alice is punished for every other honest peer she is paired with. |
The more general Volume Mutual Information (VMI) mechanism relies on the same principles of the DMI mechanism, but it uses more general mutual information measures than the magnitude of the determinant. For a joint distribution \(U\), the value of \(\operatorname{VMI}^w (U)\) is the volume of the space of less informative joint distributions, which is the set \(\downarrow U\) of all joint distributions \(U'\) for which there is a stochastic matrix \(S\) with \(SU = U'\). Because each column of the \(| C | \times | C |\) matrix \(S\) sums to one, the (Hausdorff) dimension of this space is at most \(| C | (| C | - 1)\), and the volume (Hausdorff measure) is taken at that dimension. The parameter \(w\) is the space's density, which can be freely chosen as well, and is very important to incentivize honest behavior when effort is needed to improve the agent's beliefs. The fancy formula is
There are three main reasons why these mechanisms do not resist coordinated coalitions. The first reason regards tasks of low entropy, the second ambiguous tasks and the third tasks requiring high effort.
The entropy of a task is how unpredictable its true answer is prior to reading the task description. For instance, if each task is a comparison between two random items, then each task achieves a maximum entropy of one bit. However, other tasks can have much less entropy. For instance, moderating flagged content on social media, particularly if good economic incentives are in place to regulate flagging, can result in the majority of answers to tasks, say 90% of them, to be to moderate content. The mutual information between the reports of two honest agents is much less than the maximum mutual information, which can be manufactured between two colluding agents. The collusion strategy is for collusion participants to just agree with the answers of the collusion's coordinator, which are tailored to mimic those to maximum entropy tasks.
Example. Consider the moderation tasks described above, in which 90% of flagged content should end up moderated (\(C = \left\{ \texttt{ban}, \texttt{allow} \right\}\)). Then the joint distribution matrix between two honest agents is \(\left[ \begin{array}{cc} 0.9 & 0\\ 0 & 0.1 \end{array} \right]\), assuming, of course, that all judgments are straightforward and no inaccuracies occur, which is anyway an assumption favoring the honest agents against the collusion. However, the collusion can agree on a subset of half the tasks they will vote to ban, voting to allow the remainder. Then the joint distribution matrix between two collusion members is \(\left[ \begin{array}{cc} 0.5 & 0\\ 0 & 0.5 \end{array} \right]\). But meaning the colluding mutual information is more than \(7.7\) times higher than that between honest agents. Furthermore, because of the freedom of the collusion in choosing the subset to ban, they can have \(\left[ \begin{array}{cc} 0.5 & 0\\ 0.3 & 0.1 \end{array} \right]\) as the joint distribution matrix with honest agents if they ban only content that should be banned and allow all legitimate content (but also allow violating content). This has (square-of-determinant) mutual information \(0.0025\). Therefore, if the collusion is a ratio \(f \in [0, 1]\) of the agents, honest agents are expected to be paid \[0.0081 (1 - f) + 0.0025 f = 0.0081 - 0.0056 f,\] while an agent in the collusion is expected to be paid \[ 0.0025 (1 - f) + 0.0625 f = 0.0025 + 0.06 f.\] The colluding agent's payment therefore starts to exceed that of honest ones already for \(f \approx 0.0854\), or less than \(9\%\) of agents in collusion, at which point the incentive for rational agents is no longer to be honest, but rather to join the collusion. |
Collusions are also incentivized by the difficulty of tasks. Tasks may be difficult in two principal ways: they may require effort to complete properly and they may be ambiguous. In the scenarios we present, the collusion will have a coordinator, who decides which answer all the agents in the collusion will provide. The coordinator may or may not rotate, being randomly drawn from the collusion from time to time. The cost of effort is optimized for colluding participants because it is only incurred by the coordinator, with answers simply copied by members. Furthermore, if a task is ambiguous, the mutual information between two honest agents will be less than that between two agents in the collusion and, as long as the coordinator responds honestly, the collusion members will, in expectation, have the same mutual information with non-colluding agents as would other non-colluding ones.
Example. Consider tasks consisting of fact-checking very convoluted conspiracy theories. An honest agent might have to spend, on average, one hour searching online to gather enough hard evidence to judge each conspiracy theory. However, the agents in a collusion of size \(n\) with a rotating coordinator would spend only \(1 / n\) hours on average, which is an incentive away from honest behavior and towards the collusion. |
Example. Consider nudity moderation tasks, where \(40\%\) of flagged images clearly contain nudity, \(40\%\) of them clearly don't, and the remaining \(20\%\) are borderline nude or non-nude, even by a difference of a single pixel. In these ambiguous images, imagine that honest agents cannot do better than randomly guess, even exerting effort, so their joint distribution matrix is \(\left[ \begin{array}{cc} 0.45 & 0.05\\ 0.05 & 0.45 \end{array} \right]\), of (square-of-determinant) mutual information \(0.04\). However, the coordinator of the collusion can employ the following strategy: images clearly classifiable are reported honestly, and half the ambiguous images are considered “nude,” with the other half considered “non-nude” at random. Crucially, this randomized partition is done by the coordinator and replicated by colluding members, so all colluding members always agree on every single task. Thus colluding members have a joint distribution matrix of \(\left[ \begin{array}{cc} 0.5 & 0\\ 0 & 0.5 \end{array} \right]\) between themselves but still keep the same \(\left[ \begin{array}{cc} 0.45 & 0.05\\ 0.05 & 0.45 \end{array} \right]\) matrix with honest agents. Between themselves, colluding agents achieve a higher \(0.0625\) mutual information, but keep the same \(0.04\) mutual information with other agents. Therefore, all agents are incentivized to join or remain in the collusion. |
The Mutual Information Paradigm of mechanism design is extremely powerful and generates strong truth-telling incentives. In applications that already assume non-colluding users, it is an extremely good fit. In particular, we believe it to be a better alternative to Birdwatch in a Community Notes setting, because it has formal game theoretic guarantees of truthfulness. However, using these mechanisms in a decentralized setting is risky due to the possible presence of coordinated coalitions, which can, under certain conditions, siphon resources away from the principal and agents while damaging the formation of truthful knowledge.
In the first six blog posts in this series, we introduced the key concepts and problems underlying decentralized moderation and epistemology, as well as surveyed different strategies to tackle them, including using prediction markets and mechanisms from the literature of Information Elicitation Without Verification (IEWV). The conclusion so far is that none of these methods is a perfect fit, but that they are powerful tools with plenty of application potential.
In the future, we will consider other approaches to tackling the decentralized moderation problem. As a matter of fact, we are working on an entirely different direction right now. However, for the short term, we will be taking a break in this series. If the content exposed here so far is of interest to you, feel free to reach out at hello@mbd.xyz.
Proof of Proposition 1. We have
Thus \(U_{\hat{X}_i \hat{X}_j} = SU_{X_i \hat{X}_j}\) as claimed.\(\Box\)
Yuqing Kong. Dominantly truthful multi-task peer prediction with a constant number of tasks. 2019.
Yuqing Kong. Dominantly truthful peer prediction mechanisms with a finite number of tasks. J. ACM, 71(2):9–1, 2024.
Yuqing Kong and Grant Schoenebeck. An information theoretic framework for designing information elicitation mechanisms that reward truth-telling. 2018.
Wikipedia. Stochastic matrix — Wikipedia, the free encyclopedia. https://en.wikipedia.org/wiki/Stochastic_matrix, 2024. [Online; accessed 29-October-2024].
1. In the original work, it is called an information-monotone mutual information measure.
2. More precisely, an estimator is a procedure that computes a value from samples of \(X\) and \(Y\) that equals \(\operatorname{MI} (X, Y)\) in expectation.